Xây dựng hệ thống RAG nâng cao: Từ phân tách câu hỏi đến tối ưu phản hồi AI
Trong kỷ nguyên của trí tuệ nhân tạo, việc xây dựng các hệ thống có thể hiểu và phản hồi chính xác các câu hỏi phức tạp của người dùng là vô cùng quan trọng. Bài viết này sẽ đi sâu vào quy trình xây dựng một hệ thống Retrieval Augmented Generation (RAG) nâng cao, tập trung vào kỹ thuật phân tách câu hỏi, tối ưu hóa prompt (Gom) và sử dụng các mô hình AI cục bộ như OLLAMA và VinAI 2.5 Coder 7B để đạt được hiệu quả cao nhất.
RAG nâng cao là gì và tại sao cần thiết?
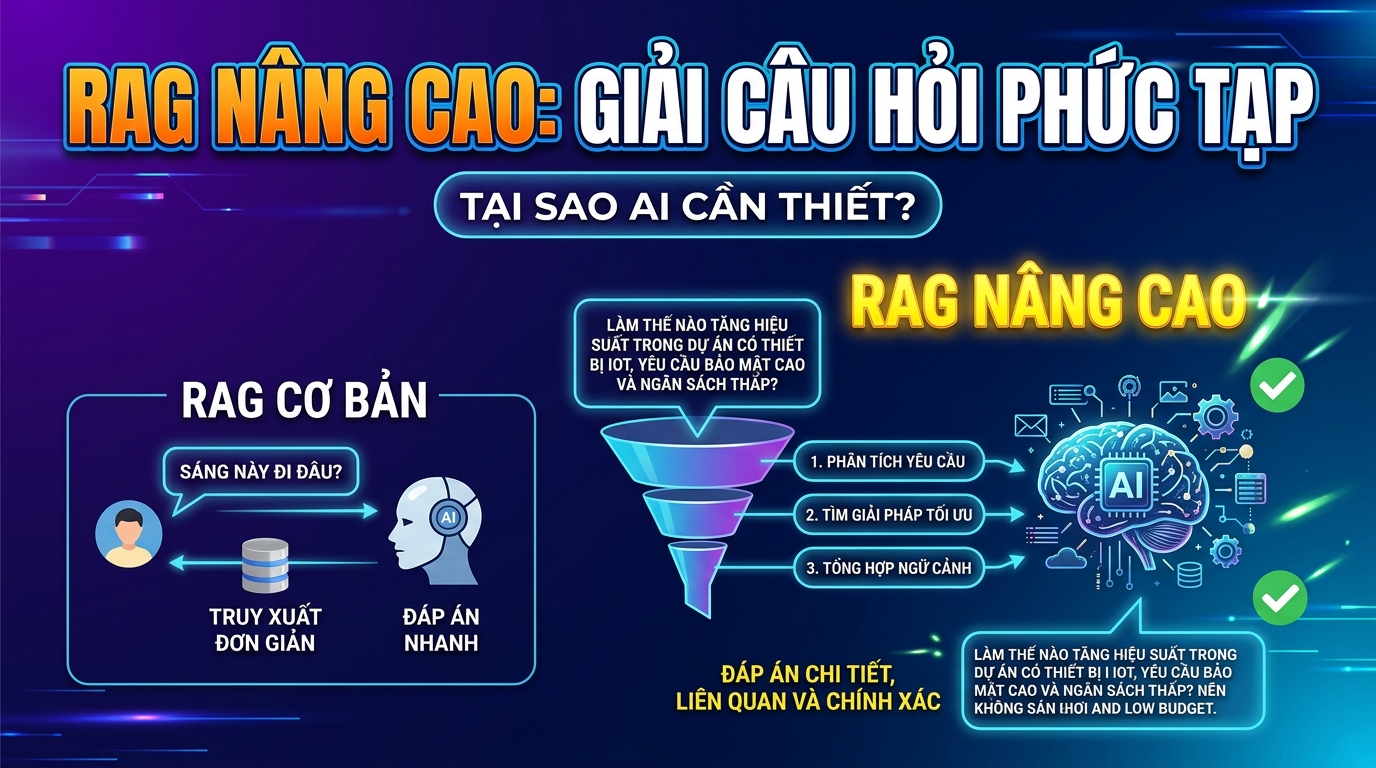
Hệ thống RAG cơ bản giúp AI truy xuất thông tin từ nguồn dữ liệu bên ngoài để tạo câu trả lời. Tuy nhiên, với những câu hỏi phức tạp, đa chiều, RAG nâng cao sẽ cần các bước xử lý tinh vi hơn để đảm bảo AI hiểu đúng ngữ cảnh và cung cấp phản hồi chính xác, liên quan. Mục tiêu là biến những câu hỏi “khó nhằn” thành các phần nhỏ hơn, dễ xử lý hơn cho AI, đồng thời tối ưu hóa quá trình tìm kiếm và tổng hợp thông tin.
Quy trình xây dựng hệ thống RAG nâng cao
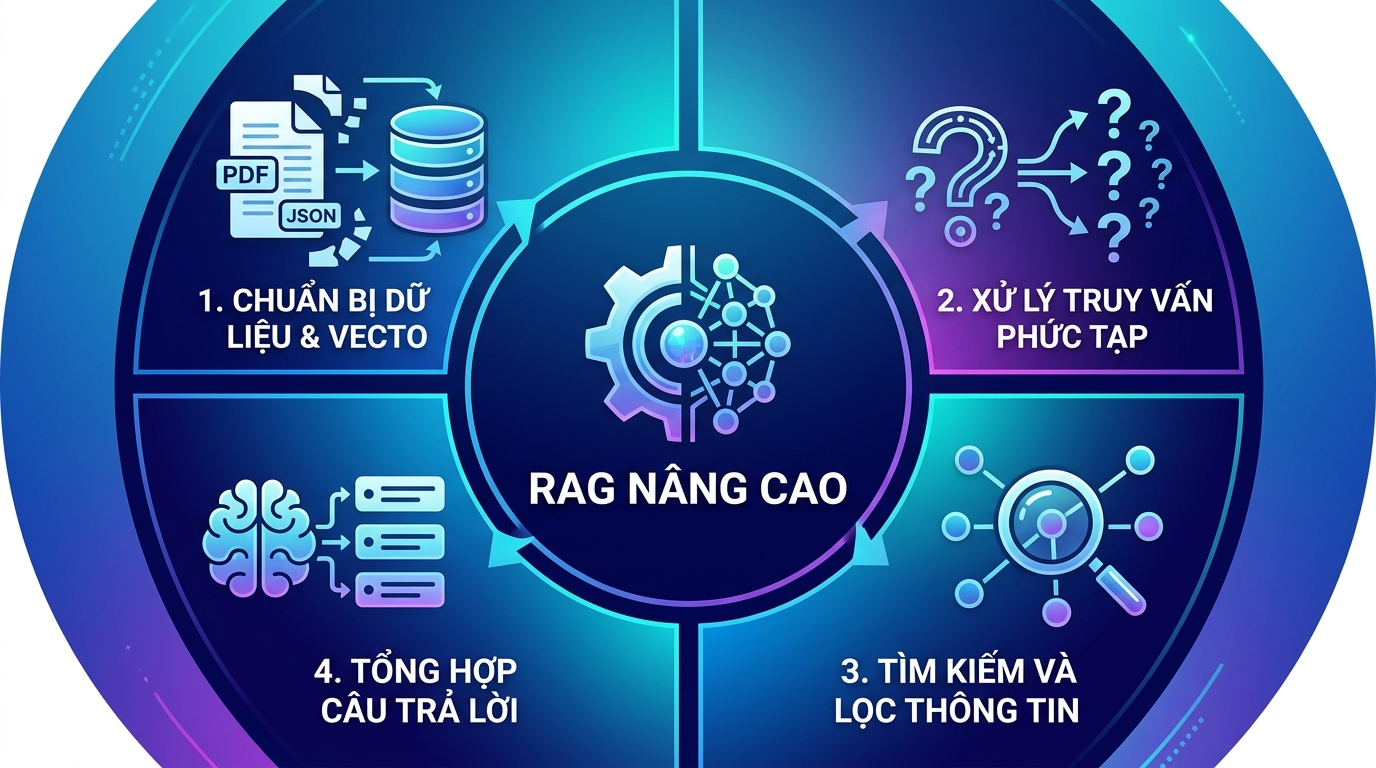
Dưới đây là các bước chi tiết để triển khai một hệ thống RAG nâng cao, giúp AI xử lý hiệu quả các truy vấn phức tạp của người dùng:
1. Chuẩn bị dữ liệu nguồn
- Tải dữ liệu: Dữ liệu có thể được lấy từ nhiều nguồn khác nhau như cơ sở dữ liệu, tệp JSON, PDF, v.v.
- Chia nhỏ dữ liệu (Chunking): Sau khi tải, dữ liệu cần được chia thành các đoạn nhỏ hơn. Tùy vào nhu cầu, bạn có thể chia nhỏ dữ liệu nhiều lần để tối ưu hóa quá trình tìm kiếm.
- Chuyển đổi thành vector và lưu trữ: Các đoạn dữ liệu đã chia nhỏ sẽ được chuyển đổi thành các vector nhúng (embedding vector) và lưu trữ vào một cơ sở dữ liệu vector hoặc tệp để tiện cho việc truy vấn sau này.
2. Xử lý câu hỏi người dùng hiệu quả
Đây là một trong những bước quan trọng nhất của RAG nâng cao, giúp AI hiểu sâu hơn về ý định của người dùng.
2.1. Phân tách câu hỏi phức tạp
- Mục tiêu: Chia một câu hỏi lớn, đa ý thành nhiều câu hỏi nhỏ hơn, đơn giản hơn.
- Cách làm: Sử dụng các mô hình AI (như OLLAMA hoặc các mô hình khác) để phân tích và tách câu hỏi.
- Ví dụ: Với câu hỏi “Thành phố Hồ Chí Minh và Cần Thơ có những món gì ngon?”, AI sẽ phân tách thành:
- “Thành phố Hồ Chí Minh có những món ăn ngon nào?”
- “Cần Thơ có những món ăn ngon nào?”
2.2. Tối ưu và mở rộng câu hỏi
- Viết lại câu hỏi: Nhờ AI viết lại các câu hỏi đã phân tách sao cho rõ nghĩa hơn, loại bỏ sự mơ hồ.
- Tạo câu hỏi mô phỏng: Yêu cầu AI tạo thêm các câu hỏi tương tự, có cùng ý nghĩa để làm phong phú thêm tập truy vấn.
2.3. Chuyển đổi câu hỏi thành vector
- Sau khi phân tách và tối ưu, các câu hỏi sẽ được chuyển đổi thành các vector nhúng tương tự như dữ liệu nguồn.
3. Tìm kiếm và chọn lọc tài liệu liên quan nhất
- So sánh vector: Sử dụng vector của câu hỏi người dùng để so sánh với các vector dữ liệu đã lưu trữ.
- Truy xuất Top N: Tìm kiếm và lấy ra N tài liệu có độ tương đồng cao nhất (top đầu) với câu hỏi.
- Lọc bỏ dữ liệu không liên quan: Từ các tài liệu Top N, tiếp tục nhờ AI kiểm tra, loại bỏ những thông tin chung chung, không thực sự liên quan hoặc có chỉ số tương đồng thấp, chỉ giữ lại các giá trị có chỉ số cao và mang ý nghĩa nhất.
4. Tổng hợp câu trả lời cuối cùng
- Tạo prompt tổng hợp: Sử dụng một prompt (Gom) đặc biệt để yêu cầu AI tổng hợp tất cả các thông tin liên quan đã chọn lọc thành một câu trả lời hoàn chỉnh, súc tích và chính xác cho câu hỏi ban đầu của người dùng.
- Chỉ định định dạng: Trong prompt, bạn có thể yêu cầu AI trả về câu trả lời theo một định dạng cụ thể (ví dụ: danh sách, đoạn văn, v.v.).
Kỹ thuật Gom (Prompt Engineering) hiệu quả

Kỹ thuật Gom đóng vai trò cực kỳ quan trọng trong toàn bộ quy trình RAG. Một Gom “chuẩn” sẽ giúp AI:
- Hiểu rõ yêu cầu.
- Thực hiện các tác vụ như phân tách, viết lại, tổng hợp một cách chính xác.
- Trả về kết quả theo đúng định dạng mong muốn.
Việc nghiên cứu và thử nghiệm các cách viết Gom khác nhau là chìa khóa để tối ưu hóa hiệu suất của hệ thống RAG.
Cài đặt và sử dụng mô hình AI cục bộ

Để vượt qua giới hạn của các phiên bản AI miễn phí và có quyền kiểm soát tốt hơn, việc cài đặt mô hình AI cục bộ là một lựa chọn tuyệt vời.
1. Cài đặt OLLAMA
- Bước 1: Cài đặt OLLAMA trên máy tính cá nhân của bạn. OLLAMA là một nền tảng cho phép chạy các mô hình ngôn ngữ lớn (LLM) cục bộ.
- Bước 2: Sau khi cài OLLAMA, bạn có thể cài đặt các mô hình AI cụ thể. Ví dụ, mô hình VinAI 2.5 Coder 7B được đề cập trong video, hoặc các mô hình khác phù hợp với cấu hình máy tính của bạn.
2. Tích hợp với môi trường phát triển
- Thiết lập API: Cấu hình một API để gửi các prompt (Gom) tới mô hình AI cục bộ và nhận phản hồi.
- Viết hàm gọi API: Phát triển các hàm (function) trong mã nguồn của bạn để tương tác với API này, gửi yêu cầu tạo embedding, phân tách câu hỏi hoặc nhận câu trả lời.
- Sử dụng trong Visual Studio Code: Bạn có thể tích hợp các mô hình AI cục bộ vào Visual Studio Code bằng cách cài đặt các tiện ích mở rộng (extension) như
continuevà cấu hình để tải mô hình AI vào một tệp cấu hình (ví dụ:CF). Sau đó, mô hình có thể được gọi và sử dụng trực tiếp trong Visual Studio Code.
Kết luận
Xây dựng hệ thống RAG nâng cao đòi hỏi sự kết hợp giữa kỹ thuật xử lý dữ liệu, kỹ năng prompt engineering và khả năng tận dụng các mô hình AI cục bộ. Bằng cách áp dụng các bước trên, bạn có thể tạo ra một hệ thống RAG mạnh mẽ, có khả năng xử lý các truy vấn phức tạp và cung cấp thông tin chính xác, mang lại giá trị cao cho người dùng. Hãy tiếp tục nghiên cứu, thử nghiệm và học hỏi từ cộng đồng để không ngừng nâng cao kiến thức và kỹ năng trong lĩnh vực AI đầy tiềm năng này.