Tự Host LLM Qwen3.5 với vLLM cho OpenClaw: Hướng dẫn chi tiết
Giới thiệu và Lợi ích
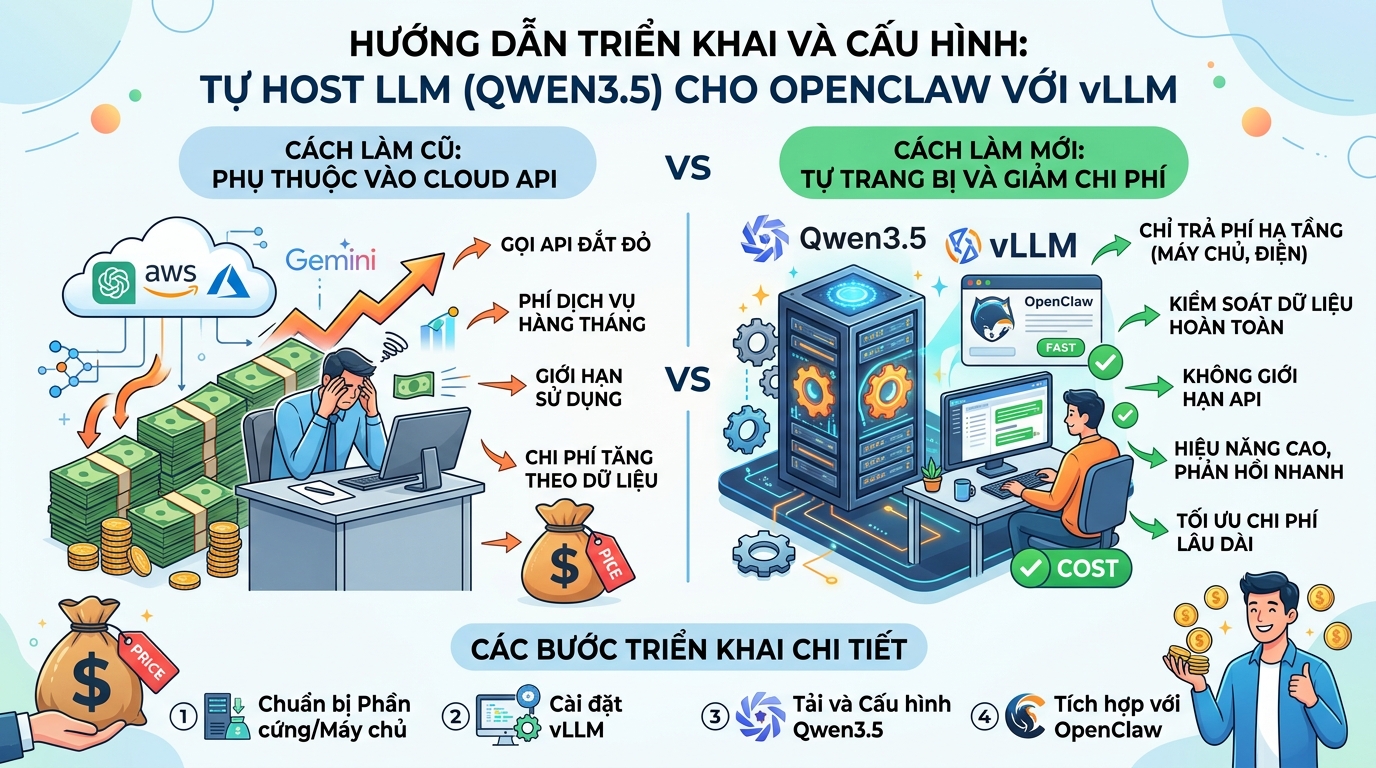
Việc tự host một mô hình ngôn ngữ lớn (LLM) như Qwen3.5 bằng vLLM cho OpenClaw giúp giảm đáng kể chi phí khi không cần gọi API lên các dịch vụ đám mây như ChatGPT, AWS, Azure hay Gemini. Hướng dẫn này sẽ tập trung vào cách triển khai và cấu hình chi tiết.
Chuẩn bị hạ tầng
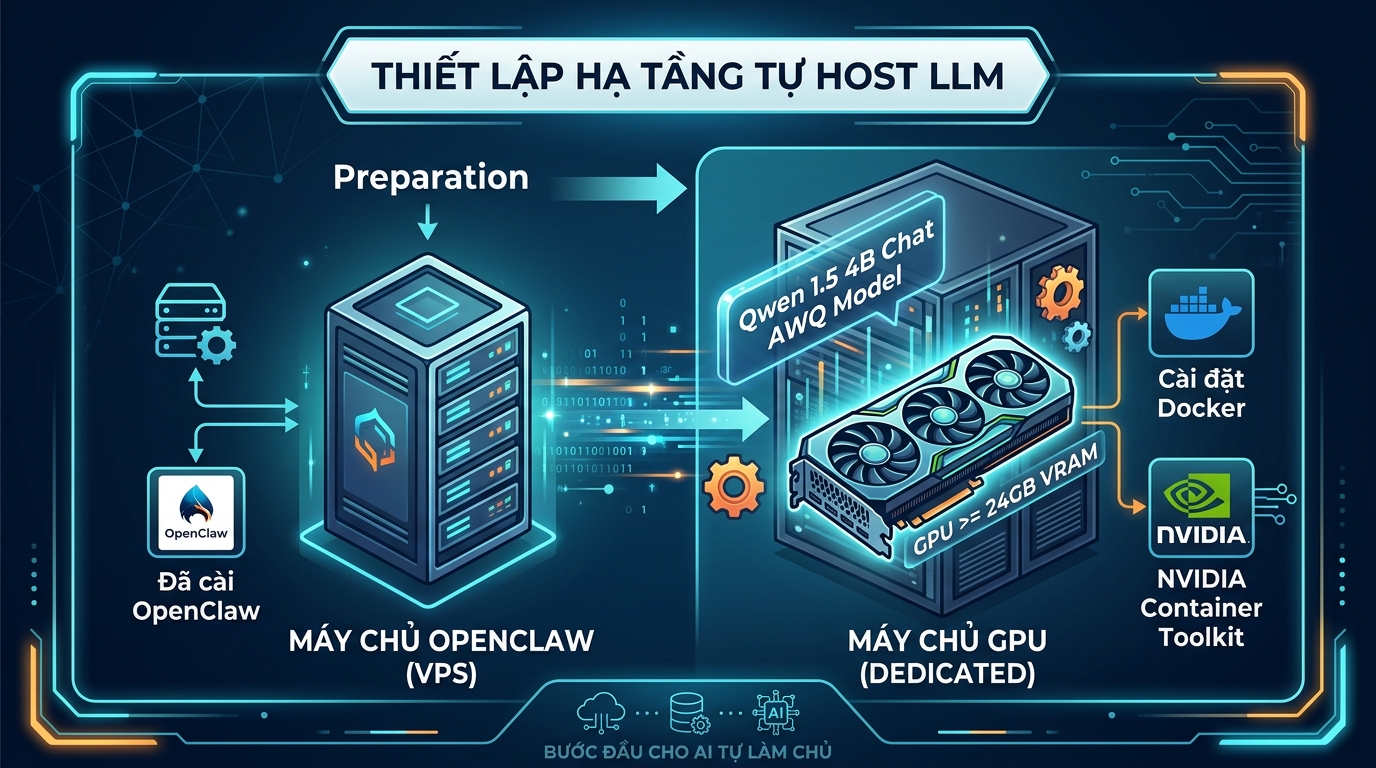
Để tự host LLM, bạn cần một máy chủ có GPU và máy chủ OpenClaw.
- Máy chủ OpenClaw: Một VPS đã cài đặt OpenClaw.
- Máy chủ GPU: Một máy chủ chuyên dụng có GPU với ít nhất 24GB VRAM để host mô hình Qwen 1.5 4B Chat AWQ.
- Cài đặt Docker và NVIDIA Container Toolkit: Đảm bảo Docker và extension để Docker truy cập GPU đã được cài đặt trên máy chủ GPU.
Chọn vLLM để triển khai mô hình
vLLM được ưu tiên sử dụng cho mục đích triển khai trong môi trường sản xuất (production) nhờ khả năng phục vụ mô hình với hiệu năng cao, tối ưu hóa tốc độ suy luận và khả năng tương thích với chuẩn API của OpenAI.
Triển khai mô hình Qwen 1.5 4B Chat AWQ với vLLM trên Docker

Chúng ta sẽ sử dụng mô hình Qwen 1.5 4B Chat AWQ (phiên bản lượng tử hóa) trên vLLM.
Bước 1: Chạy Docker Container vLLM
Thực hiện lệnh sau trên máy chủ GPU của bạn: bash docker run --gpus all -p 8888:8000 --model Qwen/Qwen1.5-4B-Chat-AWQ --auto-tool-choice --quantization awq --disable-log-stats vllm/vllm-openai:latest
--gpus all: Sử dụng tất cả các GPU có sẵn trên máy chủ.-p 8888:8000: Ánh xạ cổng 8888 của máy chủ vật lý tới cổng 8000 bên trong container Docker.--model Qwen/Qwen1.5-4B-Chat-AWQ: Chỉ định mô hình Qwen 1.5 4B Chat AWQ sẽ được tải và phục vụ.--auto-tool-choice: Bật tính năng tự động chọn công cụ, giúp OpenClaw sử dụng công cụ.--quantization awq: Sử dụng kỹ thuật lượng tử hóa AWQ để tối ưu hiệu suất và bộ nhớ.--disable-log-stats: Tắt ghi log thống kê.
Để Docker chạy ngầm (detached mode) ngay cả khi bạn đóng cửa sổ terminal, thêm tham số -d ngay sau lệnh run: bash docker run -d --gpus all -p 8888:8000 --model Qwen/Qwen1.5-4B-Chat-AWQ --auto-tool-choice --quantization awq --disable-log-stats vllm/vllm-openai:latest
Bước 2: Kiểm tra trạng thái máy chủ vLLM
Sau khi chạy lệnh Docker, chờ mô hình tải và khởi động. Khi thấy thông báo “Server started” hoặc tương tự, bạn có thể kiểm tra bằng lệnh curl: bash curl http://localhost:8888/v1/models Nếu lệnh trả về danh sách các mô hình đang được phục vụ (bao gồm Qwen1.5-4B-Chat-AWQ), nghĩa là vLLM đã hoạt động thành công.
Cấu hình OpenClaw để kết nối với vLLM

Bây giờ chúng ta sẽ cấu hình OpenClaw để gọi đến mô hình Qwen 1.5 4B Chat AWQ đang được host cục bộ. Trước tiên, bạn cần lấy địa chỉ IP của máy chủ GPU bằng lệnh ifconfig.
Cách 1: Cấu hình qua giao diện web của OpenClaw (ví dụ trên Tino.vn)
- Truy cập giao diện web của OpenClaw.
- Vào phần Cấu hình AI.
- Chọn Custom Provider và nhấn nút Thêm.
- Điền các thông tin sau:
- Model:
vlm/Qwen1.5-4B-Chat-AWQ - Tên hiển thị: (Ví dụ:
VLM Qwen 4B) - Endpoint:
http://<IP_MÁY_CHỦ_GPU>:8888/v1(Thay<IP_MÁY_CHỦ_GPU>bằng địa chỉ IP thực tế của máy chủ GPU). - API Key:
abc(hoặc bất kỳ chuỗi nào, không cần API key thực sự cho local host).
- Nhấn Tạo Custom và đợi OpenClaw khởi động lại.
- Sau khi khởi động lại, chọn mô hình
VLM Qwen 4Btrong danh sách các model có sẵn.
Cách 2: Cấu hình bằng Command Line cho OpenClaw tự cài đặt
- Trên máy chủ OpenClaw của bạn, chạy lệnh:
bash openclaw config
- Chọn Local -> Model -> vLLM.
- Khi được hỏi Base URL, nhập:
http://<IP_MÁY_CHỦ_GPU>:8888/v1 (Thay <IP_MÁY_CHỦ_GPU> bằng địa chỉ IP thực tế của máy chủ GPU).
- Khi được hỏi API Key, nhập:
abc. - Khi được hỏi vLLM Model, nhập chính xác tên mô hình:
Qwen1.5-4B-Chat-AWQ. - Xác nhận và lưu cấu hình.
Kiểm tra kết nối
Sau khi cấu hình, hãy thử trò chuyện với OpenClaw. Hệ thống sẽ gửi yêu cầu đến máy chủ GPU của bạn và sử dụng mô hình Qwen 1.5 4B Chat AWQ đã tự host để phản hồi.
Bằng cách làm theo các bước trên, bạn đã thành công tự host mô hình LLM Qwen 1.5 4B Chat AWQ bằng vLLM cho OpenClaw, giúp tối ưu chi phí và kiểm soát hoàn toàn hệ thống AI của mình.